IT-Systeme werden immer komplexer
Mit fortschreitender Digitalisierung werden unsere IT-Landschaften – wenig überraschend – immer stärker miteinander vernetzt und ihre IT-Systeme und Services über Schnittstellen miteinander gekoppelt und so immer komplexer. Eine tatsächlich existentielle Abhängigkeit zwischen zwei Systemen oder Services wird so weit wie möglich vermieden. Fällt das eine IT-System aus, muss das andere damit umgehen können und darf nicht ebenfalls ausfallen. Passiert das doch, entstehen potenziell hohe Folgekosten.

Wie teuer ist Downtime?
Aber ist ein solcher System-Ausfall wirklich so schlimm? Hier kommt es wesentlich darauf an, wo dieser Ausfall passiert. In einer 2019 durchgeführten Umfrage fand das Unternehmen ITIC heraus, dass die Kosten für eine Stunde Ausfall von kritischen IT-Systemen in den befragten Organisationen durchschnittlich mehr als 100.000 $ betragen. 86% der Organisationen gaben sogar an, dass sich diese Kosten in ihrem Umfeld auf mehr als 300.000 $ pro Stunde Ausfall summierten. Nun kann jede Organisation für sich selbst kalkulieren, ab welcher kumulierten Ausfallzeit kritischer Systeme die damit verbundenen Kosten schmerzvoll sind.
Die dunkle Seite der Macht
Eines ist sicher: Irgendwann geht in jedem IT-System etwas schief und es kann ausfallen.
Die Erfahrung zeigt: In. Jedem. System.
Warum ist das so? Wir ergreifen doch schon jede Menge Maßnahmen, um unsere IT-Systeme und Services in guter Qualität und sicher zu machen. Und das ist richtig teuer!
Technical Debt – Technische Schulden – kennt heute jeder in der IT. Irgendwann haben die Entwickler oder Integrierer eine Abkürzung genommen, um ein Problem zu lösen und den dabei entstandenen „Unrat“ nie richtig weggeräumt. Und dann die nächste Abkürzung genommen. Und die nächste. Glücklicherweise kann man Technical Debt messen, mittels statischer Code-Analyse ausfindig machen und begleichen.
Bei Dark Debt – Dunklen Schulden – geht das nicht. Dark Debt sind Fehler und Schwachstellen unserer IT-Landschaften, die sich mit statischer Code-Analyse nicht entdecken lassen. Dark Debt entdeckt man häufig erst, wenn ein Problem eintritt. Und dann ist der Schaden da.
Eine der wenigen Chancen, Dark Debt sichtbar zu machen, bevor es eintritt, besteht darin, die Bedingungen, unter denen unsere IT-Systeme und Services laufen, testweise zu verändern und zu beobachten, wie sich die Systeme und Services – auch im Zusammenspiel untereinander – verhalten. Entdecken wir auf diese Weise Schwachstellen bzw. Fehler, werden sie so weit möglich behoben oder minimiert. Wir machen unsere Systeme so widerstandsfähiger gegenüber (ungeplanten) Veränderungen.
Der Zauberspruch lautet: Resist! Widerstehe!
Resilienz bezeichnet die Fähigkeit von Systemen, auf Veränderung reagieren zu können, ohne ihre grundsätzliche Funktion zu verlieren. Im Kontext von IT-Systemen können Veränderungen vielfältig sein:
- Veränderung von
- Nutzerzahl
- Datenmenge
- Rechenaufwand
- verfügbaren Ressourcen
- Antwortzeit-Verhalten von verknüpften Systemen
- funktionale Änderungen
- Fehlerbehebungen
- eingetretene Fehler
Die Verringerung von Last z.B. durch die Verringerung der Benutzerzahl sollte von jedem IT-System ohne Schwierigkeiten gehandhabt werden können. Schwieriger wird das, wenn das IT-System so konfiguriert ist, dass in diesem Fall bisher zugesicherte Hardware-Ressourcen freigegeben werden und dem System nicht mehr zur Verfügung stehen.
Um die ganze IT-Landschaft resilient gegenüber Veränderung zu machen, muss man also herausfinden, wie ein kritisches IT-System oder im Idealfall alle kritischen Bestandteile der IT-Landschaft einer Organisation auf Fehler und andere Veränderungen reagieren, und gemäß den gewonnenen Erkenntnissen angemessene Maßnahmen ergreifen.
Chaos Engineering
Das klingt nach einer Lebensaufgabe, da eine Organisation zum einen beliebig viele kritische IT-Systeme und Services besitzen kann und zum anderen IT-Systeme durch angepasste Anforderungen und Rahmenbedingungen zur Veränderung neigen – und zwar ständig.
Eine in den vergangenen Jahren im Kontext Resilienz immer populärer gewordene Disziplin ist das Chaos Engineering. Das Wort Chaos in Chaos Engineering löst bei so manchem Verantwortlichen mangels tiefen Verständnisses des Themas Bauchschmerzen aus. Ein bewährter Weg dies zu adressieren, ist, statt von Chaos Engineering zu sprechen den Begriff Resilience Engineering zu verwenden. Schließlich ist das Ziel nicht, Chaos zu verbreiten, sondern IT-Systeme widerstandsfähig zu machen.
Das Vorgehen beim Chaos Engineering ist letztlich ein immer wiederkehrender Zyklus.
1. Architektur-Abbild
Schaffe oder aktualisiere eine Abstraktion der zu betrachtenden IT-Landschaft und den Abhängigkeiten zwischen den enthaltenen Systemen und Services.
Triff Annahmen darüber, an welchen Stellen in der IT-Landschaft potenziell Fehler und Schwachstellen enthalten sind und welche Auswirkungen diese Fehler/Schwachstellen potenziell haben.
2. Chaos Backlog
Erstelle aus diesen Fundstellen ein Backlog. Versuche die Eintrittswahrscheinlichkeit und die Auswirkung beim Eintreten des Fehlers oder beim Auslösen der Schwachstelle abzuschätzen.
Nutze diese Erkenntnisse bei der Priorisierung der Fundstellen.
3. Chaos Experiment
3.a) Überlege für den am höchsten priorisierten Eintrag des Backlog, wie du die angenommenen Auswirkungen des Fehlers/der Schwachstelle in einer kontrollierten Umgebung im Experiment nachweisen oder widerlegen kannst.
3.b) Führe das Experiment in der kontrollierten Umgebung durch und vergleiche das Ergebnis mit der ursprünglichen Erwartungshaltung.
3.c) Bist du mit dem Ergebnis zufrieden, also verhält sich das System oder der Service angemessen stabil, kannst du das Chaos Backlog Item als geschlossen betrachten. Eventuell hat das gemessene Ergebnis Auswirkungen auf andere Backlog Items und es ist notwendig diese anzupassen.
3.d) Ist das Ergebnis des Experiments nicht zufriedenstellend, passe das untersuchte System bzw. den Service so an, dass es auf das Experiment angemessen reagiert, also z.B. ohne Absturz, OutOfMemoryError usw.
3.e) Wiederhole das Experiment, um den Nachweis zu erbringen, dass die Anpassung Wirkung zeigt.
Dieser Zyklus kann/soll so oft wiederholt werden, bis das Ergebnis des Experiments zufriedenstellend ist.
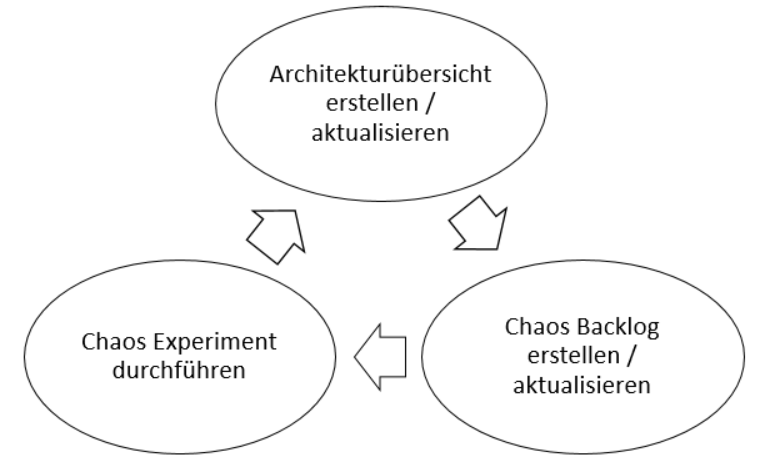
Dann geht es bei Punkt 3 oben weiter: Mit dem nächsten hoch priorisierten Backlog Item.
Je nach Organisation lohnt es sich, einmal im Quartal oder bei starker Veränderung der Systemlandschaft oder auch eines einzelnen, kritischen Systems oder Services, die Bewertung der Schwachstellen in der Architektur aus Punkt 1 oben zu wiederholen und bei Bedarf anzupassen. Das hat dann wieder Auswirkungen auf das Chaos Backlog und die Priorisierung der Backlog Items.
Tipps & Tricks
Auch beim Chaos Engineering kann man Dinge falsch machen, muss es aber nicht. Hier folgt eine Übersicht der häufigsten Fehler:
| Don‘t | Do |
| Chaos Experiment ohne Vorkenntnisse in der Produktion durchführen und so für Ausfälle sorgen | Nutze eine Umgebung, bei der ein Fehler in Folge eines Chaos Experiments möglichst keine oder wenig Auswirkung auf andere Systeme hat (Blast Radius einschränken). |
| Chaos Experiment nicht kommunizieren, sondern die Kollegen überraschen und sich deren Unmut abholen | Kommuniziere früh und offen mit den beteiligten/betroffenen Teams. Hole dir das Commitment der Leitung der Organisation ab. Kommuniziere den genauen Zeitpunkt, die Dauer und die genutzte Umgebung jedes Experiments. |
| Mehrere Experimente gleichzeitig durchführen, so dass nicht klar ist, welches Experiment welches Ergebnis beeinflusst | Führe ein Experiment zur selben Zeit auf einer Umgebung durch. |
| Zu viel Vertrauen in die eigenen Annahmen über das Verhalten des Systems/Services im Test stecken | Rechne damit, dass sich das System/der Service komplett anders verhält als angenommen. |
| Zu groß anfangen und mit einem Experiment zu viele Probleme auf einmal adressieren wollen | Starte mit einem überschaubaren Problem bei dem du (fast) sicheres Wissen über das Verhalten hast. |
Zusammenfassung
Chaos Engineering ist eine Disziplin, die uns dabei hilft, die Komplexität unserer IT-Welt beherrschbar und IT-Systeme gegen viele unvorhergesehene Änderungen widerstandsfähig zu machen. Mit einem guten Verständnis der Abhängigkeiten zwischen Systemen und Services, einem Backlog, dass potenzielle Probleme adressiert und dem Willen und der Kapazität, dieses Backlog abzuarbeiten, lässt sich die Resilienz von IT-Systemen und Services spürbar erhöhen. Der Aufwand, den eine Organisation in Chaos Engineering investiert, und die Lernkurve, die die Organisation dabei durchlaufen muss, werden sich durch weniger Ausfälle und ein besseres Verständnis der eigenen IT-Systemlandschaft in jedem Fall rentieren.